Progressive layout
- Liang Zhen
- Johann Lombardi
- Former user (Deleted)
Introduction
Progressive layout of DAOS should be fully algorithmic (no locality information is stored). The approach is based on GIGA+.
- An object with progressive layout can have different initial stripe count (1, 2, 4...)
- Each object shard stores a split version in VOS
- The initial value of split version is 0
- Split version is increased by 1 while a shard is split
- Hash range hosted by the shard can be computed out by the current split version
- The client stack always starts I/O based on the initial stripe count of object
- When the hashed dkey of the I/O request lands in the rash range, then this shard can handle this I/O, otherwise it should return the split version and reject the I/O
- Client should retry the I/O when it's rejected
- Client can cache the split version of each object shard
- A shard starts to split when number of keys within the shard reach the threshold, each shard can split independently
- Shard splitting is similar with rebuild: the new shard should pull data from the original shard
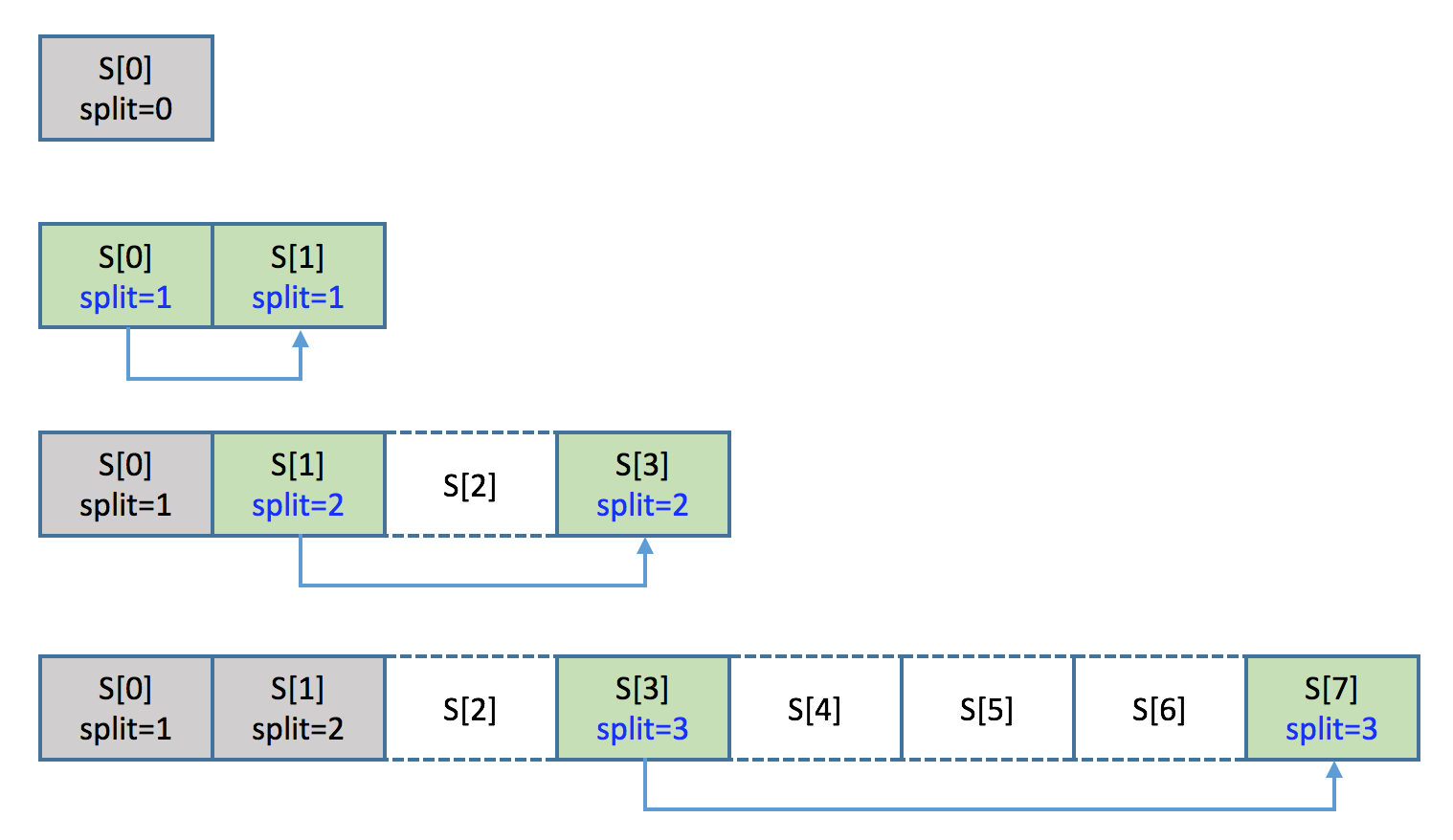
Layout change process
As described in previous section, a object shard can start to split independently when the number of dkeys hosted by this shard reach the threshold:
- The shard sends the its ID to a new target selected by algorithm
- The shard should modify its split version and flag itself as in "splitting" state
- The new shard should set itself as "constructing" and pull data from the original shard
- DAOS client should update to both new and old shard (even for those keys are not hosted by the old shard)
- DAOS client should always fetch from the old shard if it is still in splitting.
- After pulling everything, the new shard should notify the old shard to exit from "splitting"
- The old shard should reject future I/Os for the key range split out.
- The old shard should remove all keys belonging to the split key range.
- The new shard should also quit from "constructing" then it's fully functional for I/O.
Because splitting is independent, so the layout of object could be sparse. In this picture, the final layout of the object only has 4 shards, S[2, 4, 5, 6] are actually nonexistent (no replica in this diagram).
Locate a dkey
Assume caller wants to insert a new dkey, which is hashed to 0xE3

Because it's a object with progressive layout, so the client stack always send the first RPC to shard[0], if the destination shard does not host the key anymore (key range has been split), it should return its current split version. The client can compute out the new destination based on the returned split version, and try again.
- Request to S[0] (range=[0, 0xFF], split=0)
- Reply rc=ENOENT, split=1
- Compute out two hash ranges based on the returned split value: [0, 0x7F], [0x80, 0xFF]
- 0xE3 lands in the second range
- Request to S[1] (range=[0x80, 0xFF], split=1)
- Reply rc=ENOENT, split=2
- Compute out two hash ranges based on the new returned value: [0x80, 0xBF], [0xC0, 0xFF]
- 0xE3 lands in the second range
- Request to S[3] (range=[0xC0, 0xFF], split=1)
- Reply rc=ENOENT, split=3
- Computes out two hash ranges based on the returned split: [0xC0, 0xDF], [0xE0, 0xFF]
- 0xE3 lands in the second range
- Client sends request to S[7]
- Reply rc=0 (completed)
In the worst case, extra # RPCs = max(split). For example, an object has been split into 1024 shards, then it might takes 10 extra RPCs to find the key. But giving a good hash function should distribute keys evenly, so it is very likely all shards have the same split version most time, so the first RPC can return the right split version, and only 1 extra RPC is required.
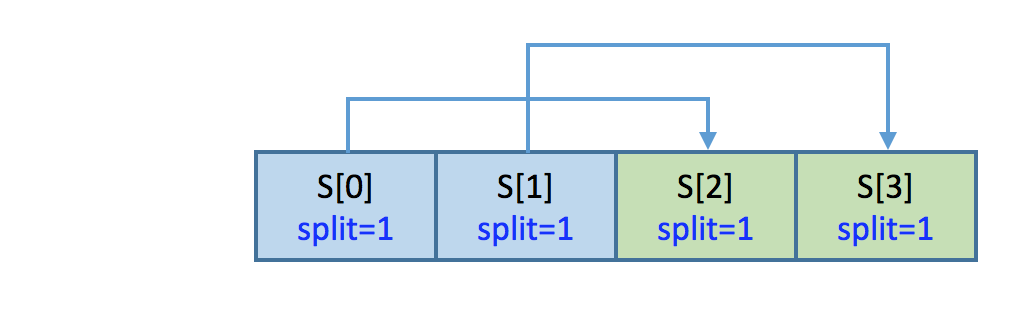
Progressive layout and rebuild
Assuming the object is 2-way replicated and has one stripe at the begin, now it starts to split (from 2 shards to 4 shards). There are two different failure cases can happen.
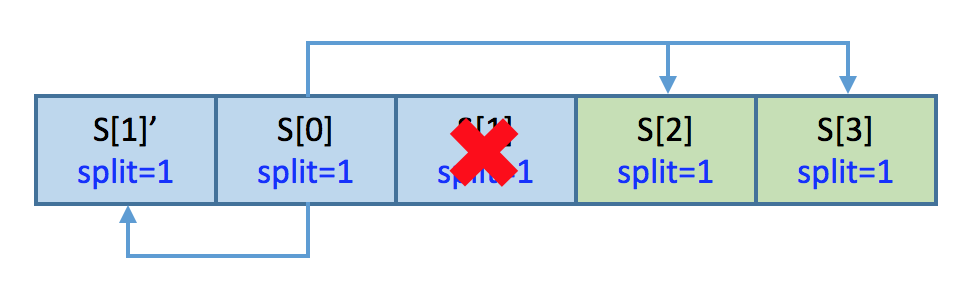
A shard in "splitting" failed
As shown in the diagram below, if shard[1] failed while splitting, the rebuild system should select a new target to rebuild shard[1]'.
- shard[1]' starts to rebuild by pulling data from shard[0]
- The degraded protocol can automatically switch all splitting I/Os to the surviving replica S[0]
- The rebuild protocal can guarantee those "constructing" shards (shard[2] and shard[3]) and client will never fetch data from shard[1]'
- Completion of rebuild and split are independent with each other
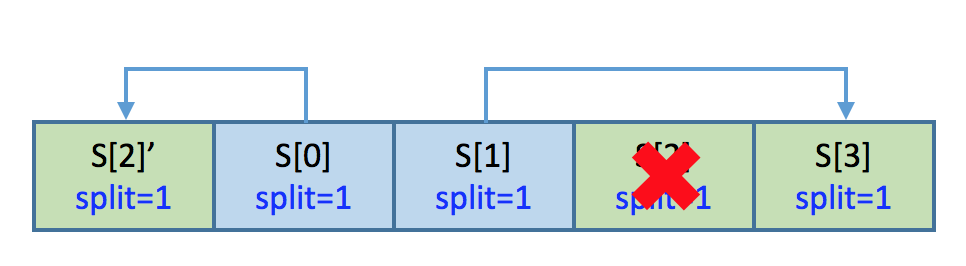
A shard in "constructing" failed
As show in the diagram, if shard[2] failed while constructing, the rebuild system should be aware of it by scanning shard[0] which is in "splitting"
- Rebuild protocol should send the shard ID to a algorithmically selected target for rebuilding a new shard[2]', this shard also should be marked as "constructing" (Rebuild protocol needs to send the status flag together with shard ID)
- Shard[2]' starts to pull data either from shard[0] or shard[1]
- Shard[2]' should follow the splitting protocol
- Only pull the data for the current split version (hash range)
- Exit from "constructing" status on completion
- Notify shard[0] to exit from "splitting" on completion
- All these happen within the rebuild cycle.